Dans le précédent article, nous avons vu comment mettre en place un compromis sur la conception objet afin d'obtenir rapidement de la persistance sur des applications dites "court terme". Nous allons maintenant aborder le pattern State-Interface qui permet la persistance de modèles du domaine parfaitement encapsulés, notamment dans le contexte d'applications plus importantes.
Dans un premier temps, nous devons définir les interfaces qui représentent les données à persister :
Remarque: comme nous utilisons EntityFramework, nous devons ajouter un champs OrderId permettant de gérer la relation de la table OrderLine vers Order.
Nous pouvons maintenant, écrire le mapping EntityFramework directement sur les classes de persistance. Aucun problème ici car les propriétés sont toutes accessibles en lecture/écriture.
Mapping OrderPersistentModel:
Mapping OrderLinePersistentModel:
Avantages :
Inconvénients :
Sommaire
- Introduction
- Faire un compromis sur la conception objet
- Le pattern State-Interface
- Le pattern State-Snapshot
- L'event sourcing
Le pattern State-Interface
Ce pattern est composé de 3 acteurs :
Voici un petit schéma pour résumer les interactions de ces acteurs.

Le pattern State-Interface se décompose en 4 étapes :
- Un Domain Model : classe qui contient de la logique métier lié à un domaine
- Un Persistent Model : classe responsable de la persistance des informations du domaine
- Une interface IModelState représentant les états commun entre Domain Model et Persistent Model. Les états du domaine à persister.
Voici un petit schéma pour résumer les interactions de ces acteurs.
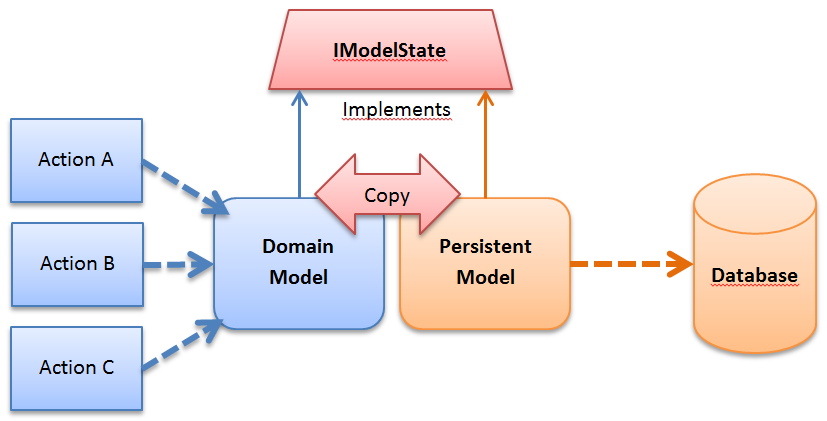
Le pattern State-Interface se décompose en 4 étapes :
- Déterminer les états du domaine à persister et en faire une interface IModelState
- Implémenter explicitement l'interface IModelState dans le Domain Model
- Implémenter normalement (implicitement) l'interface IModelState dans un Persistant Model
- Implémenter la copie d'information d'un IModelState à un autre IModelState
Adaptons l'exemple
Nous allons faire une nouvelle implémentation de notre exemple de commande de produits, en utilisant le pattern State-Interface. Nous utiliserons EntityFramework comme outil de persistance.
Dans un premier temps, nous devons définir les interfaces qui représentent les données à persister :
public interface IOrderStates<TOrderLine> where TOrderLine : IOrderLineStates
{
Guid Id { get; set; }
OrderStatus OrderStatus { get; set; }
DateTime? SubmitDate { get; set; }
double TotalCost { get; set; }
IEnumerable<TOrderLine> Lines { get; set; }
}
et public interface IOrderLineStates
{
Product Product { get; set; }
int Quantity { get; set; }
DateTime CreationDate { get; set; }
}
Nous implémentons de manière explicite IOrderStates dans la classe Order. De cette manière, nous n'exposons pas au monde extérieur ses données : public class Order : IOrderStates<OrderLine>
{
Guid IOrderStates<OrderLine>.Id
{
get { return Id; }
set { Id = value; }
}
OrderStatus IOrderStates<OrderLine>.OrderStatus
{
get { return _orderStatus; }
set { _orderStatus = value; }
}
DateTime? IOrderStates<OrderLine>.SubmitDate
{
get { return SubmitDate; }
set { SubmitDate = value; }
}
double IOrderStates<OrderLine>.TotalCost
{
get { return TotalCost; }
set { TotalCost = value; }
}
IEnumerable<OrderLine> IOrderStates<OrderLine>.Lines
{
get { return _lines.ToArray(); }
set { _lines = value.ToList(); }
}
// ...
}
De même pour la classe OrderLine avec l'interface IOrderLineStates : public class OrderLine : IOrderLineStates
{
int IOrderLineStates.Quantity
{
get { return Quantity; }
set { Quantity = value; }
}
DateTime IOrderLineStates.CreationDate
{
get { return _creationDate; }
set { _creationDate = value; }
}
Product IOrderLineStates.Product
{
get { return Product; }
set { Product = value; }
}
// ...
}
Puis dans la classe OrderPersistantModel dédiée à la persistance, nous implémentons IOrderStates de manière classique : public class OrderPersistentModel : IOrderStates<OrderLinePersistentModel>
{
public IEnumerable<OrderLinePersistentModel> Lines { get; set; }
public Guid Id { get; set; }
public OrderStatus OrderStatus { get; set; }
public DateTime? SubmitDate { get; set; }
public double TotalCost { get; set; }
public List<OrderLinePersistentModel> Lines { get; set; }
}
De même pour la classe OrderLinePersistentModel avec l'interface IOrderLineStates public class OrderLinePersistentModel : IOrderLineStates
{
public Product Product { get; set; }
public int Quantity { get; set; }
public DateTime CreationDate { get; set; }
// EF properties
public Guid OrderId { get; set; }
}
Remarque: comme nous utilisons EntityFramework, nous devons ajouter un champs OrderId permettant de gérer la relation de la table OrderLine vers Order.
Nous pouvons maintenant, écrire le mapping EntityFramework directement sur les classes de persistance. Aucun problème ici car les propriétés sont toutes accessibles en lecture/écriture.
Mapping OrderPersistentModel:
public class OrderMapping : EntityTypeConfiguration<OrderPersistentModel>
{
public OrderMapping()
{
this.ToTable("Order");
this.HasKey(x => x.Id);
this.Property(x => x.OrderStatus);
this.Property(x => x.TotalCost);
this.Property(x => x.SubmitDate);
this.HasMany(x => x.Lines).WithRequired().HasForeignKey(x=>x.OrderId);
}
}
Mapping OrderLinePersistentModel:
public class OrderLineMapping : EntityTypeConfiguration<OrderLinePersistendModel>
{
public OrderLineMapping()
{
this.ToTable("OrderLine");
this.HasKey(x => new {x.OrderId, x.Product});
this.Property(x => x.OrderId);
this.Property(x => x.Product);
this.Property(x => x.Quantity);
this.Property(x => x.CreationDate);
}
}
Maintenant que nous avons déclarer nos classes de mappings, nous pouvons implémenter le repository de la classe Order : public class EntityFrameworkOrderRepository : IOrderRepository
{
private readonly IOrderMapper _orderMapper;
public EntityFrameworkOrderRepository(IOrderMapper orderMapper)
{
_orderMapper = orderMapper;
}
public Order Get(Guid id)
{
using (var dataContext = new DataContext()) {
var persistentModel = dataContext
.Set<OrderPersistentModel>()
.Include("Lines")
.FirstOrDefault(x => x.Id == id);
if (persistentModel == null) {
return null;
}
return _orderMapper.ToDomainModel(persistentModel);
}
}
public void Add(Order order)
{
var persistentModel = _orderMapper.ToPersistentModel(order);
using (var dataContext = new DataContext()) {
dataContext.Set<OrderPersistentModel>().Add(persistentModel);
dataContext.SaveChanges();
}
}
}
Vous avez surement remarqué le méthode ToDomainModel et ToPersistentModel de l'interface IOrderMapper. C'est la dernière étape qui consiste à convertir un Order vers un OrderPersistentModel et réciproquement. Même chose pour les concepts OrderLine et OrderLinePersistentModel. Ce qui nous intéresse ici est de copier les informations de l'interface IOrderStates et IOrderLineStates.
Pour cela, plusieurs solutions :
- AutoMapper : petite librairie permettant de faire de la copie d'objets.
- Copie à la main via une méthode d'extension sur l'interface IOrderStates et IOrderLineStates
Ce code technique n'est pas très intéressant. Si vous souhaitez en savoir plus, vous pouvez jeter un coup d’œil sur l'exemple complet (Cf fin de l'article).
Un très bon article de blog d'Aurélien Boudoux présente une manière de faire grâce à une interface IMergeableCopy qui utilise la reflection pour trouver les champs d'une interface à copier.
Critique de cette approche
- La classe Order reste parfaitement encapsulée
- Il y a une séparation claire entre le modèle du domaine et le modèle de persistance (Domain model vs Persistant model)
- Les méta-données requises par les ORM pour permettre la persistance sont ajoutées dans les Persistent Models et ne polluent pas nos Domain Models.
Inconvénients :
- Une interface est sensée représenter un comportement. L'utiliser pour masquer l'état interne d'un objet n'est pas très propre.
- Le code d'implémentation implicite n'est pas très lisible dans l'objet métier Order.
- Une partie de la stratégie repose sur une copie de données d'une interface à une autre, un code technique à peu de valeur ajoutée.
Conclusion
Ce pattern est particulièrement intéressant car il crée une nette séparation entre Domain Models et Persistent Models. Nous masquons ainsi les problématiques de persistance à nos objets métiers. Nous pouvons ainsi tisser un domaine métier complexe, à travers l’interaction de nombreuses classes purement concentrées l'expression du métier.
Cependant, l'implémentation explicite de l'interface est un code technique sans valeur ajoutée qui complexifie la lisibilité de notre domaine. De plus, si à chaque objet du domaine, nous devons lier un objet de persistance, nous pouvons rapidement obtenir un très grand nombre de classes à gérer.
Tout n'est pas parfait dans ce pattern, mais je vous recommande de le tester afin de forger votre propre point de vue.
En résumé : vous êtes libre de designer vos objets du domaine comme vous le souhaitez, ... tant que vous respecter les interfaces de données.
Code
Vous pouvez retrouver l'intégralité de l'exemple avec EntityFramework et Dapper sur Github ici : https://github.com/pierregillon/DomainModelPersistencePatterns/tree/master/Patterns/StateInterface
La suite
Une autre solution intéressante et qui se rapproche beaucoup du pattern State-Interface, se nomme le State-Shapshot. Une différence ? Plus d'implémentation explicite dans nos classes métiers !
Persister l'état interne d'un objet via le pattern State-Snapshot <<





